Object Detection - RCNN
Rich feature hierarchies for accurate object detection and semantic segmentation
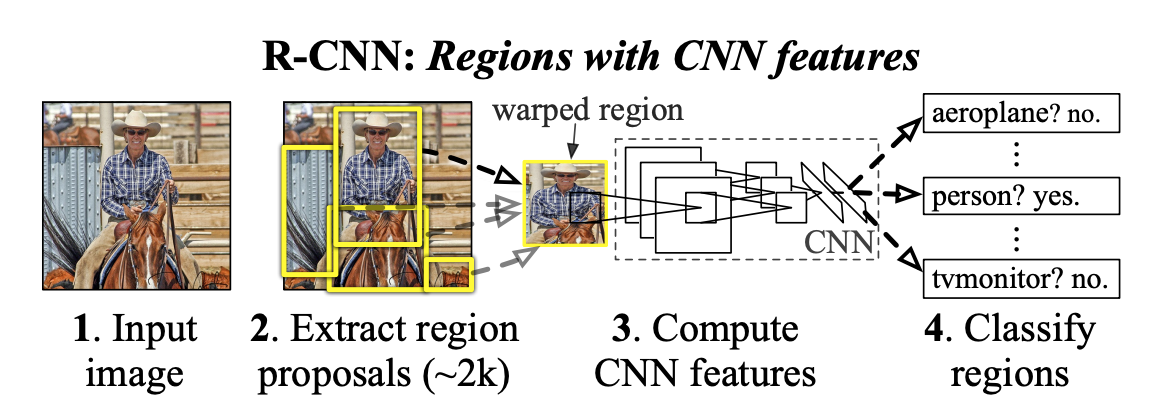
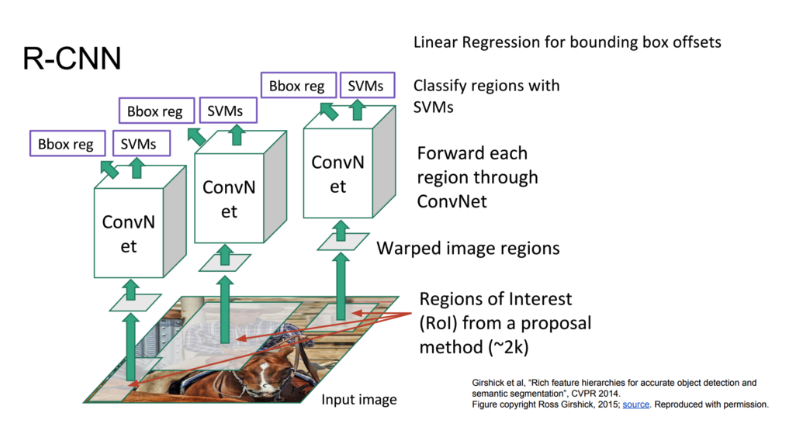
- R-CNN : Object detection algorithm
- 입력 이미지에 Selective Search 알고리즘을 적용하여 박스 추출한다. ( = 2,000 ea)
- 모든 박스를 227 x 227 크기로 리사이즈 한다.
- 미리 학습시킨 데이터를 (Image Net) 통하여 CNN을 통과시켜 4096 특징 벡터를 추출한다.
- 추출된 벡터로 각각의 클래스마다 학습시켜놓은 SVM Classifier를 통과 시킨다.
- Bounding box regression을 적용하여 Box 위치를 조정한다.
- ImageNet : 대규모(large-scale) 데이터 셋
- Selective serach algorithm
- 주변 픽셀간 유사도를 기준으로 오브젝트가 있을 법한 영역만 찾는 방법이다. ( = region proposal)
- Region proposal
- 주어진 이미지에서 물체가 있을법한 위치를 찾는 것.
- Selective search는 주변 픽셀간의 유사도를 기준으로 세그멘테이션을 생성하고, 이를 기준으로
물체가 있을법한 Box를 추론한다.
- Feature extraction
- 미리 ImageNet으로 학습된 CNN을 가져와서 Object detection 용 데이터셋으로 Fine tuning 한 뒤
Selective search 결과로 뽑힌 이미지들로부터 특징 벡터를 추출한다. - Fine tuning : CNN 층에서 추출된 벡터로 SVM 분류 학습을 시켜서 얻은 mAP 을 비교하는 것
- 미리 ImageNet으로 학습된 CNN을 가져와서 Object detection 용 데이터셋으로 Fine tuning 한 뒤
- mAP (mean average precision)
- 합성곱 신경망의 모델 성능 평가를 할 때 mAP을 이용한다.
- Precision-recall 곡선과 Average Precision은 CV에서 Object dection 알고리즘 성능 평가를 위해 사용.

1. 2개의 알고리즘이 존재한다고 가정한다.
2. 첫번째 알고리즘은 사람 인식 검출율이 99% 이지만, 한장당 10건 정도의 오검출이 발생한다.
3. 두번째 알고리즘은 사람 인식 검출율이 50% 이지만, 오검출이 미발생한다.
→ 성능 평가를 위해서는 검출율과 정확도를 동시에 고려해야 한다.
- Classification
- CNN을 통해 추출한 벡터를 가지고 각각의 클래스를 SVM Classifier 학습.
- 주어진 벡터를 놓고 해당 물체가 맞는지 아닌지를 구분하는 Classifier 모델을 학습시키는 것.
이미 학습된 CNN Classifier을 두고 왜 SVM을 별도로 학습 시킬까?
CNN Classifier를 쓰는 것이 SVM을 사용할 때보다 mAP 성능이 4%정도 낮아진다.
이것은 아마도 fine tuning 과정에서 물체의 위치 정보가 유실되고 무작위로 추출된 샘플을 학습하여
발생한것으로 보인다. (일부 저자들의 의견) → SVM을 붙여서 학습시키는 기법은 현재 사용되지 않음.
- Bounding box regression
물체 위치를 찾고, 물체 종류를 판별할 수 있는 Classification 모델을 학습 시켜서 찾아낸 박스 위치를
교정해줘서 성능을 끌어올리게 하는 행위이다.
- Box 표기법
$$ P^i=(P^i_x,P^i_y,P^i_w,P^i_h) $$
- Ground Truth에 해당하는 Box 표기법
$$ G = (G_x,G_y,G_w,G_h) $$
-. x, y는 점이기 때문에 이미지의 크기에 상관없이 위치만 이동시켜주면 된다.
-. 너비와 높이는 이미지의 크기에 비례하여 조정해야 함.
-. 위 두가지 특성을 반영하여 P를 이동시키는 함수의 식을 작성하면 아래와 같다.
$$ G_x = P_wdx(P)+Px $$
$$ G_y = P_hdy(P)+Py $$
$$ G_w = P_wexp(dw(P) $$
$$ G_h=P_hexp(dh(P)) $$
우리가 학습을 통해서 얻고자 하는 함수는 'd 함수' 다
- 저자들은 이 d 함수를 구하기 위해 CNN을 통과할 때 pool5 레이어에서 얻어낸 특징 벡터를 사용하고,
함수에 학습 가능한 웨이트 벡터를 주어 계산한다.
$$ d_x(P) = w^t_x\phi_5(P) $$
- 웨이트를 학습 시킬 Loss Function을 세워보면 다음과 같다.
- 일반적인 MSE Error Function에 L2 normalization을 추가한 형태다. (람다 1000으로 설정)
$$ w_x = argmin\sum_{i}^{N}(t^i_x - w^T_x\phi_5(P^i))^2+\lambda||w_x||^2 $$
- t는 P를 G로 이동시키기 위해서 이동량을 의미한다. 식은 아래와 같다.
$$ t_x=(G_x - P_x)/P_w \\ t_y=(G_y-P_y)/P_h\\ t_w=log(G_w/P_w)\\ t_h=log(G_h/P_h) $$
- CNN을 통과하여 추출된 벡터와 x,y w,h를 조정하는 함수의 웨이트를 곱해서 Bounding Box를 조정해주는
선형 회귀를 학습시키는 것이다.
- R-CNN 학습
- Image Net으로 이미 학습된 모델을 가져와 Fine tuing 하는 부분
- SVM Calssifier를 학습시키는 부분
- Bounding Box Regression
- 속도 저하의 가장 큰 병목 구간은 Selective Search를 통한 2000개의 영역을 모두 CNN infenrence를 진행하기 때문임.
- R-CNN은 Image 1개당 GPU에서 약 13초, CPU에서 약 50초가 소요됨.